
Vuoi una AI (Intelligenza Artificiale) o un Assistente Virtuale Intelligente che si basa su chatGPT perché hai capito che è fondamentale per il tuo business?
Certamente una AI di alto livello migliorerà i risultati complessivi della tua azienda.
Non integrarne una nei processi di business significherà perdere terreno già nel breve periodo rispetto ai concorrenti, anche più piccoli, che la utilizzeranno.
chatGPT sta facendo un lavoro gigantesco nel far capire cosa si può fare con l’AI e dove è arrivata oggi, ma non è (ancora) lo strumento su cui basare l’Assistente Virtuale della tua azienda.
Vediamo insieme perché nel resto dell’articolo e quali alternative puoi trovare.
Premesse
Per meglio di capire la natura dei limiti dell’uso aziendale di chatGPT dobbiamo prima approfondire:
- cosa sa e cosa non sa
- come adattarlo alla nostra azienda
Cosa è e cosa sa
1. chatGPT è un chatbot di OpenAI basato sul motore generativo GPT-3 (userò questa versione semplificata, al posto di GPT-3.5, talvolta usata)
ovvero, per dirla in parole semplici
è un derivato, specializzato per un dialogo, di un più generale modello di linguaggio, orientato alla generazione di testi.
GPT-3 è stato addestrato, (con una enormità di frasi corrispondente a quasi 3 milioni di libri di circa 250 pagine), ad identificare:
- parole oscurate nella frase corrente
- la più probabile frase successiva a quella corrente, tra un insieme di candidati
Tradotto in italiano, questo ci dice che:
- ha imparato relazioni ed analogie verbali e tra frasi, possiede una sorta di conoscenza enciclopedica, ma “solo” per associazione, per concetti simili
- non capisce nulla, anche se sembra che capisca e la sua conoscenza non è strutturata, non ricorda dati come ci hanno abituati i database o anche solo i fogli di calcolo
È come un bambino in età prescolare: sa, ma non sa cosa sa e perché lo sa e, spesso, fa confusione perché certi concetti sono più grossi di lui.
In realtà l’esempio è sfavorevole:
- al bambino, perché in molti casi effettivamente un bambino, pur piccolo, capisce
- al modello di AI perché ha una base di conoscenza più estesa (infatti apparentemente “sa” tutto)
Come adattarlo alla nostra azienda
2. chatGPT non può essere oggi addestrato con nuove informazioni e non può essere utilizzato direttamente all’interno di un programma aziendale, ma GPT-3 non presenta questi limiti: può imparare partendo da liste di domande e risposte d’esempio e può essere richiamato come servizio a pagamento utilizzando interfacce software su Internet (API)
Anche per chatGPT sono state annunciate API e possibilità di integrare l’apprendimento, ma non sono ad oggi note.
Di conseguenza in questo articolo per semplicità indicheremo chatGPT e GPT-3 come chatGPT, a meno che non serva espressamente distinguerli.
Attraverso le API disponibili noi possiamo inviare delle istruzioni (prompt), in italiano ed ottenere delle risposte.
In chatGPT i prompt corrispondono alle frasi del dialogo, ma se ne scegliamo accuratamente le singole parole (prompt engineering) è possibile ottenere risultati molto più precisi e vicini a quanto ci serve.
L’estensione del training si chiama più propriamente fine tuning, ed è una sorta di specializzazione della conoscenza, che non sostituisce la precedente, ma la integra.
Può servire, per esempio, a far conoscere ad una versione a noi dedicata di chatGPT le attività della nostra azienda e le caratteristiche dei prodotti che vendiamo.
Teniamo presente che:
- Il training ha un costo dipendente dalla quantità di testo fornito
- la versione di chatGPT addestrata costa più di quella generica e si paga sul testo totale tra domanda e risposta
- per fortuna il fine tuning è incrementale: se dovessero servire nuovi esempi basta aggiungerli
Cosa potrebbe mai andare storto?
Limiti
Se hai letto fin qui, probabilmente hai già capito da te o avrai letto altrove dei molti vantaggi di chatGPT.
Con le basi del paragrafo precedente possiamo ora affrontare i limiti di questa piattaforma, se calata in ambito aziendale.
Faremo l’ipotesi di gestire una azienda alimentare, che vuole proporre i suoi prodotti, evidenziando la bontà dei propri ingredienti in un sito di e-commerce.
Vedremo nei successivi sottoparagrafi che tipo di problemi potremmo incontrare.
Allucinazioni
chatGPT talvolta genera dati inventati o errati, (allucina, si dice, ovvero soffre di allucinazioni), tipicamente legati a contesti simili, ma differenti.
Prendiamo l’esempio seguente (ma ne troverai molti cercando su Internet):
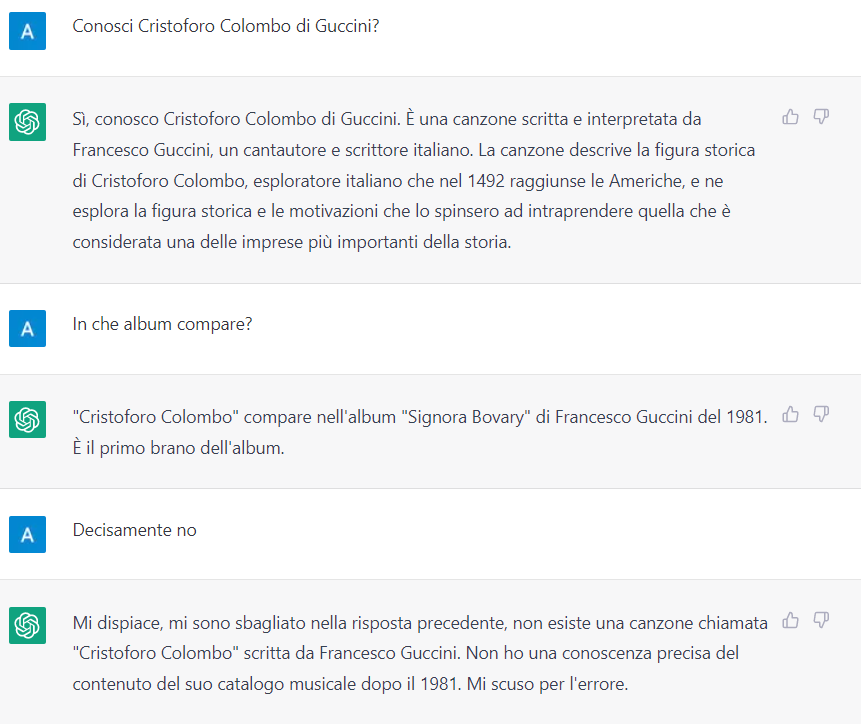
In realtà la canzone è del 2004, è contenuta nell’album Ritratti, di cui è il sesto brano.
Per capire come mai chatGPT sbaglia così malamente, dobbiamo rifarci alle premesse.
Il punto è che non memorizza conoscenza strutturata, ma associa parole e frasi che erano vicine durante il training.
Non sarebbe strano che i testi che parlano della discografia di Guccini contengano sia Signora Bovary che Cristoforo Colombo.
Associando staticamente parole e frasi senza capirle, con esempi ridotti e non specifici per la risposta attesa, farà più errori.
Al contrario, ovviamente, migliora se aumentano i testi che contengono le informazioni, perché aumenta la statistica favorevole.
Ora, veniamo alla nostra azienda di alimentari:
- Possiamo permetterci che confonda la descrizione di un prodotto con un altro, aggiungendo la panna alla carbonara?
- O che confonda un ingrediente con un altro, tra quelli che gli forniamo? Potrebbe essere grave per utenti con allergie.
- Apposite tecniche di prompt engineering permettono di ridurre gli effetti di allucinazione, ma senza eliminarli, al momento.
- L’informazione presente nel training dovrà essere molto consistente, per evitare confusioni. Ma quanto? Dipende dalla quantità di prodotti, dalla sovrapposizione delle loro descrizioni e dei loro ingredienti. Più sono sovrapposti, più informazioni serviranno per poter discriminare. Conviene pensare (o farci suggerire da chatGPT!) a tutte le domande possibili sull’argomento. Lo scopo è rafforzare le associazioni che più ci interessano. Quantità e qualità dipenderanno dal contesto e probabilmente si dovrà operare per approssimazioni successive.
Scarso controllo dell’output e bias
Anche in mancanza di allucinazioni, chatGPT potrebbe fornire risposte non gradite alla nostra azienda.
Senza un fine tuning sufficiente, le nostre informazioni si confonderebbero statisticamente con quelle del suo training principale.
Peggio sarebbe non fornirgli un fine tuning su argomenti importanti per la nostra azienda alimentare. O, ancora, se decidessimo di far rispondere a lui, tanto “le caratteristiche generali degli ingredienti le conosce già.”
Potremmo essere sorpresi da frasi “corrette” in senso generale, ma magari poco piacevoli per il nostro business. Per esempio potrebbe:
- suggerire una tecnologia che usa un concorrente
- fornire informazioni su alcuni ingredienti che, mal interpretate, potrebbero generarci un danno economico.
Proviamo un esempio pratico che potrebbe dare problemi alla nostra azienda alimentare:
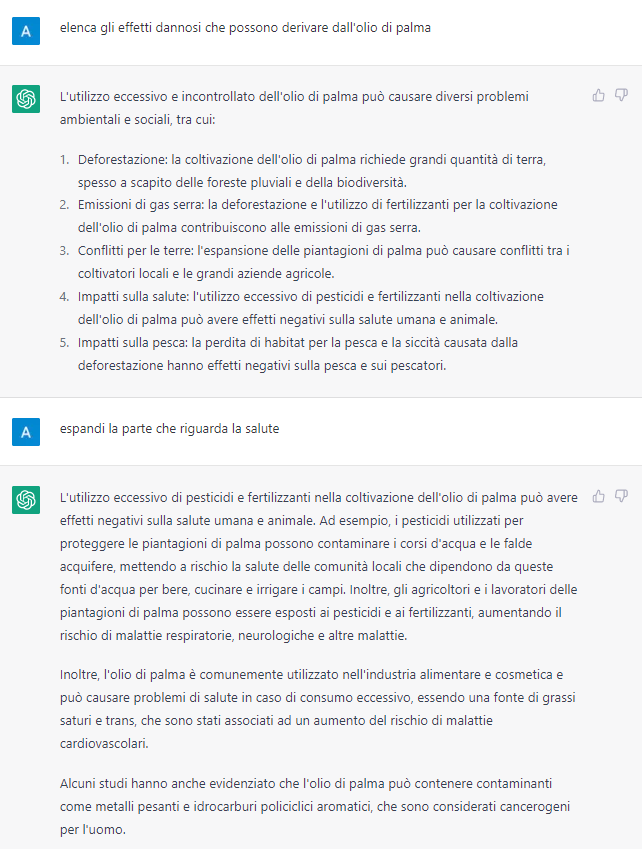
Aziende più note della nostra hanno già dovuto, in passato, attivare poderose campagne informative e cause legali su questo argomento specifico, investendo parecchio denaro, per ridurre gli effetti negativi di informazioni anche valide in una situazione generica, ma non necessariamente applicabili allo specifico contesto.
Lasciare che lo dica direttamente il nostro Assistente Virtuale, dal nostro sito, significa andarsi a cercare i problemi da soli.
Ricordiamoci sempre che un chatbot (o Assistente Virtuale Intelligente, meglio) rappresenta la nostra azienda, in quel momento: quello che dice, lo diciamo noi, è una delle punte del nostro marketing e della nostra comunicazione.
Problema simile si pone ancora di più con i bias (in italiano potremmo chiamarli preconcetti)
Derivano dal fatto che, su tali dimensioni informative, è estremamente complesso filtrare le informazioni alla fonte, per renderle politically correct.
OpenAI ha lavorato molto bene, aggiungendo filtri più espliciti per evitare che il modello generativo riceva input errati.
Hanno anche ideato una API apposita per gestire moderare i contenuti, ma è probabile che chatGPT ne usi una sua.
Tali filtri però, presentano due problemi:
- rischiano di limitare anche le interazioni lecite
- sono stati aggirati e sono tuttora aggirabili.
Sarebbe spiacevole dover “spegnere” il nostro Assistente Virtuale il giorno dopo averlo attivato, per evitare danni di immagine.
Non è una ipotesi, è già successo ad altri più grandi ed esperti di informatica della nostra azienda alimentare.
In un altro articolo abbiamo già suggerito un approccio neuro-simbolico per casi simili, ma qui non possiamo applicarlo direttamente.
Dati dinamici
Supponiamo di poter gestire e/o accettare gli errori rimanenti.
Non ci resta che integrarlo con il nostro sito di e-commerce, per aiutare i clienti a completare l’acquisto.
Abbiamo visto che chatGPT può imparare le informazioni statiche sulla nostra azienda ed i nostri prodotti.
Ci piacerebbe, però, che potesse anche:
- leggere il prezzo ed evidenziare all’utente che è ridotto rispetto alla settimana precedente
- dire se il prodotto è nel carrello
- chiarire che restano pochi pezzi a magazzino, ma ci si aspetta di averne a sufficienza per domani
- spiegare perché non può essere applicato un certo sconto
- aiutare l’utente con le funzionalità della pagina in cui si trova
- fare up-selling e cross-selling, basandosi sulle preferenze dell’utente
Peccato, purtroppo non può.
Lui impara solo e può rispondere solo su quanto gli è stato fornito in fase di training o fine tuning.
Lavora solo con dati statici, non con dati dinamici.
Di conseguenza:
- non può integrarsi con i nostri sistemi aziendali o con sistemi esterni
- in caso di variazioni nelle informazioni un fine tuning incrementale aumenterebbe solo la confusione
- non può leggere i dati del database per l’inventario o il carrello dell’utente
- non conosce il contesto in cui si sta muovendo l’utente
È improbabile che le attese future API di chatGPT rendano possibile integrarsi con sistemi esterni, perché il problema è architetturale:
- manca un punto di azione dopo il riconoscimento della richiesta utente (“quanti pezzi di rigatoni ho nel carrello?”)
- non è esplicitamente prevista l’individuazione di specifiche entità (merce, “rigatoni”; unità di misura, i “pezzi” – e non i “kg”)
- per poi usarle come parametri per interrogare il sistema di e-commerce che gestisce il carrello
- ottenere il dato richiesto
- ricomporre la frase di risposta
Eppure un Assistente Virtuale mediamente evoluto è in grado normalmente di fare queste operazioni:
- riconoscimento dell’Intent (con percentuali che superano anche il 96-97% di accuratezza, coi giusti dati)
- estrazione delle entità (con tecniche di NER, Named Entity Recognition o anche con semplici regular expression)
- interrogazione del sistema di e-commerce (perché architetturalmente aperto alle integrazioni)
- recupero della quantità
- ricomposizione della frase (anche se, tipicamente, con meccanismi spesso più rigidi e meno fluenti di quelle di chatGPT)
Per ottenere il meglio dei due sistemi si potrebbe, per esempio:
- trattare i punti da 1 a 4 con meccanismi standard
- chiedere a chatGPT di tradurre il dato strutturato ottenuto in una frase in italiano come solo lui sa fare
Anzi, potremmo anche chiedergli di usare il tu o il lei e ricordargli che l’interlocutore ha detto di essere donna.
Ma sarebbero due sistemi integrati, non chatGPT da solo, avremmo aggirato il suo funzionamento standard.
NOTA: anche la piattaforma di Assistenti Virtuali deve essere aperta e flessibile per integrare il suo output con chatGPT.
Ovviamente quella di Algaware può farlo: quella della tua azienda, pure?
Sessioni parallele
“Ma come”, ti starai chiedendo, “Che problema potrebbe esserci? chatGTP già gestisce il dialogo con milioni di utenti in parallelo!”
Questo sottoparagrafo è totalmente tecnico, per quanto semplificato: se non sei un informatico e pure con un minimo di esperienza, per il tuo bene ti consiglio di saltarla. Sei avvisato.
Supponiamo di aver risolto i problemi precedenti.
Ora abbiamo 100 utenti che stanno comprando sul nostro sistema.
Ma come facciamo a mantenere un dialogo coerente con il nostro chatGPT?
Su un sistema gestionale (Web) classico, a fronte di 100 utenti, le connessioni al database non saranno 100, ma, diciamo, 10. Vengono prese da un connection pool, perché sono risorse “costose” in termini di carico sui sistemi e, spesso, di licenze.
Nel caso di chatGPT al momento è previsto un utente per ogni dialogo ed è lui a gestire la conversazione.
Ma non possiamo aprire nuove utenze dinamicamente (almeno non al momento) e non possiamo neppure permetterci che i nostri utenti vedano uno le conversazioni dell’altro o che ci sia confusione in questo senso.
A noi servono utenti dinamici e un contesto coerente, come fare?
Con GPT-3, bisogna fornire tutto il contesto: a differenza di chatGPT lui non mantiene memoria delle precedenti richieste.
Ma quanto contesto dobbiamo fornire a GPT-3, per avere un dialogo coerente?
Dovremo fornirgli tutte le informazioni raccolte in precedenza, che potrebbero servire per ottenere una risposta completa e complessa.
Ricordiamo, però, che più contesto vuol dire più caratteri, trasmettendo ogni volta informazioni già inviate, quindi costi che salgono, apparentemente inutilmente.
E comunque, questo contesto da dove lo recuperiamo, se non abbiamo un sistema che è in grado di riconoscere la frase ed estrarre le informazioni che ci servono?
Sì, sto dicendo che anche per mantenere più sessioni in parallelo con GPT-3 è oggi necessario avere una piattaforma di Assistenti Virtuali che sia in grado (v. paragrafo precedente) di comprendere l’intent, poi estrarre le entità etc. etc., cui dobbiamo aggiungere il task di mantenere il contesto.
Le future API di chatGPT risolveranno questo problema?
Ipotizzo di sì: per esempio, potrebbero lasciare una sola utenza, ma con degli identificativi di sessione multipli.
In questo modo potrebbe totalizzare i consumi senza farci impazzire, ma anche abilitare un dialogo coerente con ognuno.
Ma sono ipotesi personali: al momento queste API non ci sono e non sappiamo con certezza cosa faranno.
Memoria
GPT-3 non riesce a lavorare su testi lunghi: tra domanda e risposta può trattare al massimo 4000 token, circa 16000 caratteri, in inglese, ovvero circa 15-16 pagine.
ChatGPT eredita gli stessi limiti e, di fatto, si comporta come se venisse fornita a GPT-3 l’ultima parte del dialogo.
Poi dimentica.
Non potrebbe analizzare molti contratti commerciali, riassumere libri o interpretare sentenze di tribunale, per esempio.
Attività che altri sistemi di NLP sono in grado di gestire.
Però per l’e-commerce della nostra azienda di alimentari dovrebbe bastare.
A meno che non si tratti di gestire utenti che ritornano: chatGPT non “ricorda” nuove informazioni oltre la sessione corrente.
Per non perdere l’opportunità di fare proposte commerciali efficaci, però, il nostro Assistente Virtuale dovrebbe ricordare:
- il nome dell’interlocutore
- il fatto che sia allergico a qualche ingrediente
- se ha già fatto acquisti presso la piattaforma
- che l’utente ha già espresso una passione per i carciofi
Ancora una volta ci serve una piattaforma esterna, progettata per sfruttare meglio memoria e dialogo, anche attraverso le diverse sessioni.
Mancanza di ragionamento
Dal nostro sito di e-commerce vorremmo poter rispondere a domande semplici tipo “se ordino oggi, per quando riceverò la merce?”
Ci serve un ragionamento banale, tipo: aggiungere ad oggi i tempi di consegna medi e spostare il risultato al primo giorno lavorativo disponibile.
chatGPT non ragiona e se sembra farlo è perché sta riproponendo ragionamenti già visti, semplicemente rintracciando statisticamente termini associati.
Non capisce cosa sta dicendo e non è infrequente che gli apparenti ragionamenti risultanti siano incoerenti rispetto ai dati.
Infatti non applica un algoritmo o un processo, ma si limita a concatenare parole che stanno bene assieme.
Normalmente non sono richieste capacità di ragionamento vere e proprie ad un Assistente Virtuale.
Semplicemente gli Assistenti Virtuali sono preparati a rispondere alle richieste più frequenti e i “ragionamenti” seguono flussi pre-definiti.
In quanto pre-definiti, effettivamente possono applicare algoritmi e processi ai dati, ma questa attività implica le solite capacità di:
- estrarre informazioni strutturate dal testo del dialogo
- da fornire alle diverse procedure che “simulano” il ragionamento.
Rispondere alla domanda dell’esempio ricadrebbe facilmente in questa casistica, facilmente gestibile da una piattaforma di Assistenti Virtuali appena nella media.
Anche in questo caso servirebbe una piattaforma a parte, per ovviare ai suoi limiti.
Conclusioni
Tutti gli esempi precedenti devono essere, allo stato attuale, considerati non come limiti specifici del solo chatGPT, ma comuni a tutti i modelli generativi attuali.
Oggi chatGPT è uno dei migliori esempi di questo approccio in circolazione: le problematiche indicate sono proprie dell’architettura scelta.
Come continuiamo a ripetere, però, utilizzare solo deep learning è una scelta architetturale, ma non è l’unica.
Sarebbe possibile mitigare i limiti indicati con tecniche neuro-simboliche, ovvero approcci che estendono il deep learning con tecniche di AI simbolica.
Oltre a quanto visto, si potrebbero aggiungere capacità di ragionamento esplicito, gestione formale della conoscenza e molto altro.
Continuiamo a ripetere anche che in un approccio neuro-simbolico, per parallelismo con quanto accade in un essere umano, è come se, logicamente:
- il deep learning corrisponda alle nostre sensazioni, sentimenti, intuizioni, analogie ed associazioni che spesso non sappiamo spiegare (come accade con chatGPT)
- l’AI simbolica integri con aspetti simili a quelli della razionalità cosciente umana, che rianalizza e corregge le intuizioni, filtrandole con l’esperienza, le regole e rappresentazioni razionali del mondo che ci siamo fatti
L’intelligenza umana non può fare a meno di uno dei due aspetti sopra esposti e neppure quella artificiale.
Ricordiamo, inoltre, che attendiamo a breve l’uscita di GPT-4, di cui è stato oramai detto tutto ed il contrario di tutto.
GPT-4, o qualche altro prossimo LLM (Large Language Model), potrebbe mostrare la comparsa di ulteriori capacità che normalmente consideriamo intelligenti.
Si è già visto qualcosa di simile con i training multipli applicati da Google in PaLM.
Tali modelli potrebbero anche superare i limiti qui evidenziati.
Potenzialmente, nonostante molti lo ritengano “teoricamente” non possibile, potrebbero risolvere col solo deep learning problematiche che oggi richiedono approcci neuro-simbolici.
La verità è che non abbiamo abbastanza informazioni e bisognerà aspettare i prossimi modelli e metterli alla prova.
Sappiamo però che l’AI cambierà sempre più velocemente sé stessa, le nostre aziende, il lavoro e la società intera.
E sarebbe meglio essere pronti, flessibili e utilizzare i vantaggi forniti da queste tecnologie man mano che sono disponibili.











Leave a reply